IceQream
iceqream.RmdIntroduction
IceQream (Interpretable Computational Engine for Quantitative Regression of Enhancer ATAC Motifs) is a package for regressing accessibility from DNA sequences. It models TF effective concentrations as latent variables that activate or repress regulatory elements in a nonlinear fashion, with possible contribution from pairwise interactions and synergistic chromosomal domain effects.
This vignette demonstrates how to use IceQream to analyze chromosome accessibility data, focusing on a sample of 5000 loci from a mouse gastrulation trajectory from Epiblast to Early nascent mesoderm. This analysis can help identify key regulatory elements and transcription factors involved in cellular differentiation processes, and understand quantitatively how they contribute to the observed changes in chromatin accessibility.
Setup and Data Preparation
First, let’s load the necessary packages and set up our environment:
Creating a misha genome
We will start by creating a misha database for mm10 genome. If you
already have an mm10 misha database you can skip this part
and load the genome using gsetroot("path/to/mm10").
gdb.create_genome("mm10")
gsetroot("mm10")Downloading Example Data
See below for minimal instructions on how to use IceQream on your own data.
For this tutorial, we’ll use pre-prepared data from a sample of the mouse gastrulation trajectory. Let’s download and load this data:
download.file("https://iceqream.s3.eu-west-1.amazonaws.com/gastrulation-example.tar.gz", "gastrulation-example.tar.gz")
untar("gastrulation-example.tar.gz")
peak_intervals <- readr::read_rds("gastrulation-example/peak_intervals.rds")
atac_scores <- readr::read_rds("gastrulation-example/atac_scores.rds")
additional_features <- readr::read_rds("gastrulation-example/additional_features.rds")
normalization_intervals <- readr::read_tsv("gastrulation-example/gastrulation_intervals.tsv", show_col_types = FALSE)Let’s examine the structure of our input data:
# Peak intervals
head(peak_intervals)
#> # A tibble: 6 × 6
#> chrom start end peak_name const tss_dist
#> <chr> <dbl> <dbl> <chr> <lgl> <dbl>
#> 1 chrX 162915760 162916060 5289_Ctps2_58 FALSE 13589
#> 2 chr14 102806560 102806860 1627_Lmo7_1306 FALSE 8155
#> 3 chr18 74739880 74740180 2390_Myo5b_32 FALSE 6115
#> 4 chr5 98166060 98166360 3695_Fgf5_4 FALSE -14508
#> 5 chr7 26775960 26776260 4228_Nlrp9c_413 FALSE 18818
#> 6 chr10 28636080 28636380 432_Ptprk_786 FALSE -31979
# ATAC scores
head(atac_scores)
#> bin1 bin2 bin3 bin4
#> 5289_Ctps2_58 0.28664573 0.21607409 0.15598945 0.18531872
#> 1627_Lmo7_1306 0.06559805 0.10535270 0.14138811 0.18453988
#> 2390_Myo5b_32 0.01259770 0.01340993 0.02850534 0.03999234
#> 3695_Fgf5_4 0.35906208 0.37084859 0.49515351 0.83097388
#> 4228_Nlrp9c_413 0.75004775 0.64881577 0.41868309 0.32506901
#> 432_Ptprk_786 0.36038245 0.22897889 0.18171044 0.02891232
# Additional features
head(additional_features)
#> cg_cont k4me3 k27me3 k27ac prox_bin1_punc_all
#> 5289_Ctps2_58 0.73947831 0.9540617 5.733111 2.062427 0.5903188
#> 1627_Lmo7_1306 1.88216323 0.9540617 3.094265 2.976209 0.6168619
#> 2390_Myo5b_32 0.61229329 0.9540617 2.149111 1.387341 0.5680226
#> 3695_Fgf5_4 2.68143918 6.3160307 10.000000 1.387341 7.2356519
#> 4228_Nlrp9c_413 0.84718098 0.9540617 2.370734 5.132278 3.4941350
#> 432_Ptprk_786 0.07383385 1.0416816 2.422208 2.062427 0.8716757
#> spatial_ratio TT CT GT AT TC
#> 5289_Ctps2_58 8.701846 3.7500 3.863636 4.827586 5.714286 3.783784
#> 1627_Lmo7_1306 6.416438 3.1250 5.000000 5.172414 4.285714 4.594595
#> 2390_Myo5b_32 5.030319 4.6875 5.681818 5.862069 4.285714 3.513514
#> 3695_Fgf5_4 6.429673 3.7500 6.136364 3.793103 7.500000 6.216216
#> 4228_Nlrp9c_413 8.757560 3.1250 4.318182 10.000000 3.928571 3.783784
#> 432_Ptprk_786 7.862827 3.4375 3.181818 3.448276 3.571429 2.162162
#> CC GC AC TG CG GG
#> 5289_Ctps2_58 4.358974 2.448980 6.551724 4.210526 0.7317073 4.615385
#> 1627_Lmo7_1306 3.076923 3.877551 4.827586 5.789474 2.4390244 4.871795
#> 2390_Myo5b_32 4.102564 4.489796 5.172414 7.631579 0.4878049 4.871795
#> 3695_Fgf5_4 5.641026 5.918367 3.448276 7.368421 3.1707317 4.102564
#> 4228_Nlrp9c_413 4.358974 3.469388 3.448276 10.000000 0.9756098 4.102564
#> 432_Ptprk_786 2.307692 6.326531 5.517241 4.210526 0.0000000 2.051282
#> AG TA CA GA AA
#> 5289_Ctps2_58 6.888889 6.666667 6.578947 6.216216 7.1875
#> 1627_Lmo7_1306 7.333333 3.703704 5.000000 8.378378 5.9375
#> 2390_Myo5b_32 6.444444 4.444444 6.315789 5.405405 4.3750
#> 3695_Fgf5_4 3.111111 2.962963 6.052632 3.783784 2.1875
#> 4228_Nlrp9c_413 4.888889 3.703704 4.736842 4.324324 1.8750
#> 432_Ptprk_786 8.444444 3.703704 10.000000 3.513514 10.0000The peak_intervals dataframe contains the genomic
positions of accessibility peaks. The atac_scores matrix
contains ATAC-seq signal intensities for each peak across different
stages of the trajectory. additional_features includes
extra genomic features for each peak.
Computing Motif Energies
The first step in the IceQream pipeline is to compute motif energies for each transcription factor model and each peak. This process can be computationally intensive, as it calculates energies for over 20,000 motifs from various databases.
motif_energies <- compute_motif_energies(peak_intervals, motif_db, normalization_intervals = normalization_intervals)However, for this tutorial, we’re using pre-computed motif energies for a sample of 5000 loci, which are included in the example data:
motif_energies <- readr::read_rds("gastrulation-example/motif_energies.rds")
print(paste("Motif energy matrix dimensions:", paste(dim(motif_energies), collapse = " x ")))
#> [1] "Motif energy matrix dimensions: 5000 x 21862"This pre-computed matrix contains motif energies for our sample of peaks, allowing us to proceed with the analysis more quickly.
For a less memory and computationally intensive analysis on your own data, you can reduce the number of motifs used in the regression by taking a representative from the SCENIC clusters (1615) instead of all motifs (20,000+). This can be done by:
motif_energies <- compute_motif_energies(peak_intervals, motif_db_scenic_clusters, normalization_intervals = normalization_intervals)Running IceQream
Now we’re ready to run the IceQream regression:
traj_model <- iq_regression(
peak_intervals = peak_intervals,
atac_scores = atac_scores,
motif_energies = motif_energies,
normalize_energies = FALSE,
additional_features = additional_features,
norm_intervals = normalization_intervals,
seed = 60427,
n_prego_motifs = 0, # increase to include de-novo motifs
frac_train = 0.8,
max_motif_num = 30
# include_interactions = TRUE # uncomment to include pairwise interactions
)
#> → Computing sequence features
#> → Added the following sequence features: "gc_content"
#> ℹ Seed: 60427
#> ℹ Training on 4000 intervals (80%) and testing on 1000 intervals (20%)
#> → Regressing on train set
#> Warning in regress_trajectory_motifs(peak_intervals =
#> peak_intervals[train_idxs, : NA values in additional features are
#> replaced with 0
#> ℹ Number of peaks: 4000
#> → Extracting sequences...
#> ℹ Calculating correlations between 21862 motif energies and ATAC difference...
#> ℹ Selected 3953 (out of 21862) features with absolute correlation >= 0.05
#> ℹ Running first round of regression, # of features: 3953
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning: glmnet.fit: algorithm did not converge
#> ℹ Taking 3507 features with beta >= 0.003
#> ℹ Running second round of regression...
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> ℹ Clustering 3481 features into 30 clusters...
#> ℹ Choosing top 30 features clusters
#> ℹ Features left: 3481
#> ℹ Learning a model for each motif cluster...
#> ℹ Infering energies...
#> ℹ Running final regression, number of features: 212
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> ✔ Finished running model. Number of non-zero coefficients: 211 (out of 212). R^2: 0.504542585994142
#> Warning in infer_trajectory_motifs(traj_model, peak_intervals[test_idxs, :
#> NA values in additional features are replaced with 0
#> ℹ Extracting sequences...
#> ℹ Computing motif energies for 1000 intervals and 129963 normalization intervals
#> ℹ Inferring the model on 1000 intervals
#>
#> Number of motifs: 30
#> R^2 train: 0.505
#> R^2 test: 0.431
#>
#> → Filtering the model
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> ℹ Using 400 samples for filtering
#> ℹ R^2 of the full model: 0.26471276009439
#> ℹ Filtering features with R^2 < 5e-04 and bits < 1.75
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.neph__UW.Motif.0639 (----CCAGATGGC--): 0.0053114662552623. Bits: 8.75317222394556
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.kznf__ZNF18_Imbeault2017_OM_RCADE (-----TTCACA----): -0.00609024711598499. Bits: 4.18059267354316
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.homer__CYHATAAAAN_Hoxa13 (--TAAACAAT-----): -0.00755734992889961. Bits: 7.5120405108336
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.taipale_cyt_meth__POU2F2_NTMATTATGCAN_eDBD (AGAACGTATAAC-G-): -0.00477077746767879. Bits: 11.2679045953488
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by JASPAR.GATA2 (------GATA-----): 0.0649994763981358. Bits: 5.54057132789097
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by JASPAR.TBX1 (----A-GTGT-A---): 0.0349019487090572. Bits: 6.19088779594984
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.neph__UW.Motif.0188 (-----TTAGCAT-A-): 0.0125507420122338. Bits: 4.60903694894758
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.taipale__PITX1_DBD_NYTAATCCN_repr (------G-TTA----): -0.000229831888005683. Bits: 2.43085755936834
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.neph__UW.Motif.0048 (---GCAGCTGA----): 0.0115380360517521. Bits: 10.9552580058168
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by JASPAR.TREE1 (---AAT--AATTA--): 0.00890760150668563. Bits: 6.8232229178626
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.taipale_cyt_meth__BHLHE23_ANCATATGNT_FL_meth (-----CAG-TG----): 0.0308563362913034. Bits: 3.52185013914139
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.cisbp__M01881 (------A--------): -0.0051392040329214. Bits: 0.982104266776725
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.cisbp__M01739 (-----ACG-G-----): -0.0023785973444807. Bits: 1.69777930799667
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.cisbp__M00066 (---AGGAGCT-----): 0.000750668141963784. Bits: 8.49950791809433
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.kznf__CTCF_ENCODE.57_ChIP-seq (----ATATAAAT---): -0.00356426248534908. Bits: 6.89524344652503
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.swissregulon__hs__ESR2 (---GA-GTGA-----): 0.00993127937489308. Bits: 3.63134155570285
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.transfac_public__M00410 (----ACAATA-----): 0.018705854274112. Bits: 6.53478029315037
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.cisbp__M00002 (----CCACAT-----): -0.00321088183338142. Bits: 4.34496513502578
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.taipale_cyt_meth__LHX4_NTAATTAN_FL_repr (---CAATTA------): 0.00703918510075618. Bits: 3.6098580621109
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.cisbp__M01529 (------CAC-C----): -0.000990912243812925. Bits: 2.82911658703759
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.hocomoco__ZBT18_HUMAN.H11MO.0.C (---GCAGCTGGG---): 0.00377658271386416. Bits: 12.1202327607881
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by HOCOMOCO.NF2L1_MOUSE.H11MO.0.C (---GTGA-G------): 0.00383742709239399. Bits: 2.95109101802874
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.predrem__nrMotif2250 (-----ACGTCA----): 0.00427600708915621. Bits: 3.22082429964159
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.cisbp__M00006 (-----CAGGTA----): 0.00408747150173144. Bits: 7.89670582132685
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by JOLMA.MESP1_di_DBD (-----A-CAGGTG--): 0.0120032264645258. Bits: 5.77623064152554
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.predrem__nrMotif1099 (----TG-GAAC----): -0.00269704238353569. Bits: 3.03185523955961
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.predrem__nrMotif1859 (----A-GTGC-----): -0.00216658726730673. Bits: 2.45546591878619
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.taipale_cyt_meth__ISL2_SCACTTAN_eDBD (---TCAAAT------): -0.00757289862138033. Bits: 3.79337988175124
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.cisbp__M02099 (-----TAATCAG---): 0.00312152015653916. Bits: 7.72754426020812
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → R^2 added by SCENIC.scertf__morozov.MGA1 (-----ATCAAAG---): 0.014784902490846. Bits: 6.16790935062072
#> ℹ Removing the following features with bits < 1.75: "SCENIC.cisbp__M01881" and "SCENIC.cisbp__M01739"
#> ℹ Trying to remove the following features with R^2 < 5e-04: "SCENIC.kznf__ZNF18_Imbeault2017_OM_RCADE", "SCENIC.homer__CYHATAAAAN_Hoxa13", "SCENIC.taipale_cyt_meth__POU2F2_NTMATTATGCAN_eDBD", "SCENIC.taipale__PITX1_DBD_NYTAATCCN_repr", "SCENIC.cisbp__M01881", "SCENIC.cisbp__M01739", "SCENIC.kznf__CTCF_ENCODE.57_ChIP-seq", "SCENIC.cisbp__M00002", "SCENIC.cisbp__M01529", "SCENIC.predrem__nrMotif1099", "SCENIC.predrem__nrMotif1859", and "SCENIC.taipale_cyt_meth__ISL2_SCACTTAN_eDBD"
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning: glmnet.fit: algorithm did not converge
#> → Removing "SCENIC.homer__CYHATAAAAN_Hoxa13" changed the R^2 by -0.00140863108016637
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → Removing "SCENIC.kznf__ZNF18_Imbeault2017_OM_RCADE" changed the R^2 by -0.0114790091067073
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → Removing "SCENIC.taipale_cyt_meth__POU2F2_NTMATTATGCAN_eDBD" changed the R^2 by -0.00481583011296888
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → Not removing "SCENIC.kznf__CTCF_ENCODE.57_ChIP-seq" (changed the R^2 by only 0.000858728358122618).
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → Removing "SCENIC.cisbp__M00002" changed the R^2 by -0.00587542016164483
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → Removing "SCENIC.predrem__nrMotif1099" changed the R^2 by -0.00359112644278642
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → Removing "SCENIC.predrem__nrMotif1859" changed the R^2 by -0.00129434665084743
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → Removing "SCENIC.cisbp__M01529" changed the R^2 by -0.0017851803050557
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> → Not removing "SCENIC.taipale__PITX1_DBD_NYTAATCCN_repr" (changed the R^2 by only 0.0032051656166816).
#> ℹ Removed 2 features with bits < 1.75
#> ℹ Removed 8 features with R^2 < 5e-04
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning in eval(family$initialize): glmnet.fit: algorithm did not converge
#> ✔ After filtering: Number of non-zero coefficients: 170 (out of 172). R^2: 0.494160731764211. Number of models: 20
#> Warning in infer_trajectory_motifs(traj_model, peak_intervals[test_idxs, :
#> NA values in additional features are replaced with 0
#> ℹ Extracting sequences...
#> ℹ Computing motif energies for 1000 intervals and 129963 normalization intervals
#> ℹ Inferring the model on 1000 intervals
#>
#> Number of motifs: 20
#> R^2 train: 0.494
#> R^2 test: 0.426
#>
#> ✔ Finished IQ regression
#>
#> Run `plot_traj_model_report(traj_model)` to visualize the model features
#> Run `plot_prediction_scatter(traj_model)` to visualize the model predictionsLet’s examine the output:
print(traj_model)
#> <TrajectoryModel> with 20 motifs and 23 additional features
#>
#> Slots include:
#> • @model: A GLM model object. Number of non-zero coefficients: 170
#> • @motif_models: A named list of motif models. Each element contains PSSM and
#> spatial model (20 models: "SCENIC.neph__UW.Motif.0639", "JASPAR.GATA2",
#> "JASPAR.TBX1", "SCENIC.neph__UW.Motif.0188",
#> "SCENIC.taipale__PITX1_DBD_NYTAATCCN_repr", "SCENIC.neph__UW.Motif.0048",
#> "JASPAR.TREE1", "SCENIC.taipale_cyt_meth__BHLHE23_ANCATATGNT_FL_meth",
#> "SCENIC.cisbp__M00066", "SCENIC.kznf__CTCF_ENCODE.57_ChIP-seq",
#> "SCENIC.swissregulon__hs__ESR2", "SCENIC.transfac_public__M00410",
#> "SCENIC.taipale_cyt_meth__LHX4_NTAATTAN_FL_repr",
#> "SCENIC.hocomoco__ZBT18_HUMAN.H11MO.0.C", "HOCOMOCO.NF2L1_MOUSE.H11MO.0.C",
#> "SCENIC.predrem__nrMotif2250", "SCENIC.cisbp__M00006", "JOLMA.MESP1_di_DBD",
#> "SCENIC.cisbp__M02099", and "SCENIC.scertf__morozov.MGA1")
#> • @additional_features: A data frame of additional features (23 features)
#> • @coefs: A data frame of coefficients (43 elements)
#> • @model_features: A matrix of the model features (logistic functions of the
#> motif models energies, dimensions: 5000x172)
#> • @normalized_energies: A matrix of normalized energies of the model features
#> (dimensions: 5000x20)
#> • @type: A vector the length of the number of peaks, indicating whether each
#> peak is a training ('train') or a prediction peak ('test')
#> • @diff_score: A numeric value representing the difference score the model was
#> trained on (5000 elements)
#> • @predicted_diff_score: A numeric value representing the predicted difference
#> score
#> • @initial_prego_models: A list of prego models used in the initial phase of
#> the algorithm (0 models)
#> • @peak_intervals: A data frame containing the peak intervals (5000 elements)
#> • @normalization_intervals: A data frame containing the intervals used for
#> energy normalization (129963 elements)
#> • @features_r2: A numeric vector of the added R^2 values for each feature (20
#> elements)
#> • @params: A list of parameters used for training (including:
#> "energy_norm_quantile", "norm_energy_max", "min_energy", "alpha", "lambda",
#> "peaks_size", "spat_num_bins", "spat_bin_size", "distilled_features",
#> "n_clust_factor", "include_interactions", "interaction_threshold",
#> "symmetrize_spat", "seed", "stats", "features_bits", "r2_threshold", and
#> "bits_threshold")
#>
#> R^2 train: 0.494
#> R^2 test: 0.426The TrajectoryModel object contains components such as
the regression model, motif models, and predicted accessibility
scores.
Visualizing Results
Let’s start with a scatter plot of observed vs. predicted accessibility changes:
plot_prediction_scatter(traj_model)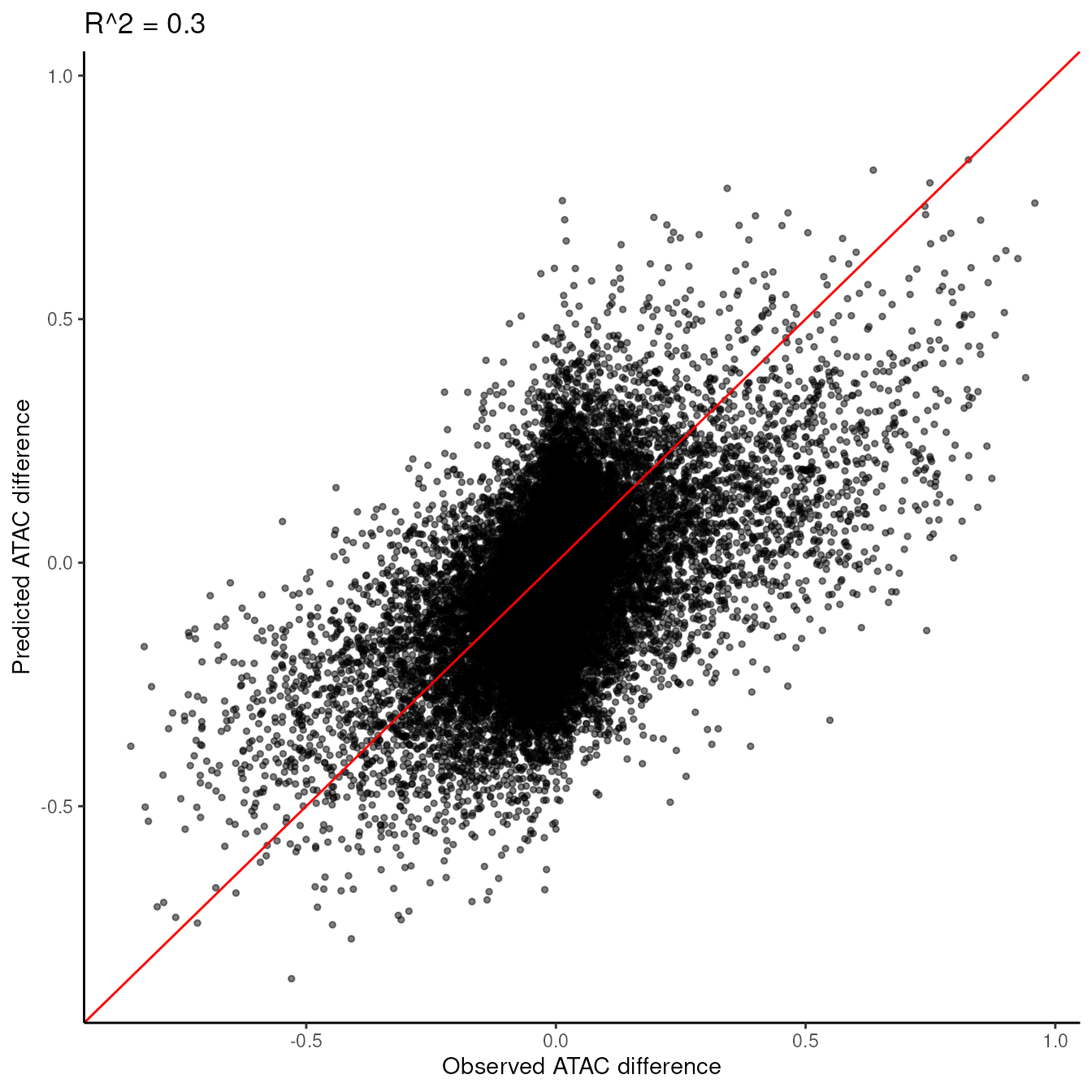
This plot shows how well our model predicts accessibility changes. Points closer to the diagonal line indicate better predictions. We measure the accuracy of the model using the coefficient of determination (R^2).
Model report
Next, let’s look at the model report, which provides detailed information about the motifs and their contributions:
plot_traj_model_report(traj_model, filename = "model_report.pdf")
knitr::include_graphics("model_report.pdf")Interpreting the trajectory model report
The model report provides several key pieces of information (from left to right):
- Motif logos show the inferred sequence preferences for each transcription factor model.
- Response curves show how the accessibility changes as a function of binding energy for each TF.
- Barplots show the coefficient of each non-linear term of every motif in the model.
- Spatial model curves show the parameters of the spatial model for each TF. The R² values indicate the predictive power each TF adds to the model.
- Spatial curves show the frequency of each TF binding site along the peaks from the bottom 10% (blue) and top 10% (red) of the differential accessibility (dAP) distribution.
- Boxplots show the distribution of ATAC differences (dAP, y-axis) for bins of binding energy (x-axis) for each TF.
Renaming the motif models
You can rename the motif models to more informative names, either
manually using rename_motif_models or automatically using
match_traj_model_motif_names:
names_map <- match_traj_model_motif_names(traj_model)
#> ℹ Matching motif names, note that this might take a while.
#> → Matching SCENIC.neph__UW.Motif.0639
#> → Matched with "HOMER.Atoh1", PSSM correlation = 0.753213203757469
#> → Matching JASPAR.GATA2
#> → Matched with "HOMER.GATA3_2", PSSM correlation = 0.925460717193095
#> → Matching JASPAR.TBX1
#> → Matched with "HOMER.Tbet", PSSM correlation = 0.81366742234409
#> → Matching SCENIC.neph__UW.Motif.0188
#> → Matched with "HOMER.Oct4", PSSM correlation = 0.819132006659473
#> → Matching SCENIC.taipale__PITX1_DBD_NYTAATCCN_repr
#> → Matched with "HOMER.GSC", PSSM correlation = 0.796165760752198
#> → Matching SCENIC.neph__UW.Motif.0048
#> → Matched with "HOMER.Ptf1a", PSSM correlation = 0.744259745311024
#> → Matching JASPAR.TREE1
#> → Matched with "HOMER.CES_1", PSSM correlation = 0.822638055016751
#> → Matching SCENIC.taipale_cyt_meth__BHLHE23_ANCATATGNT_FL_meth
#> → Matched with "HOMER.HLH_1", PSSM correlation = 0.827300202414477
#> → Matching SCENIC.cisbp__M00066
#> → Matched with "HOMER.PU_1", PSSM correlation = 0.553375609592903
#> → Matching SCENIC.kznf__CTCF_ENCODE.57_ChIP-seq
#> → Matched with "HOMER.SeqBias_A", PSSM correlation = 0.716960968207738
#> → Matching SCENIC.swissregulon__hs__ESR2
#> → Matched with "HOMER.Tbx5", PSSM correlation = 0.651863264990547
#> → Matching SCENIC.transfac_public__M00410
#> → Matched with "HOMER.Oct2", PSSM correlation = 0.616286342232992
#> → Matching SCENIC.taipale_cyt_meth__LHX4_NTAATTAN_FL_repr
#> → Matched with "HOMER.Lhx3", PSSM correlation = 0.673309344193721
#> → Matching SCENIC.hocomoco__ZBT18_HUMAN.H11MO.0.C
#> → Matched with "HOMER.E2A", PSSM correlation = 0.888876703642631
#> → Matching HOCOMOCO.NF2L1_MOUSE.H11MO.0.C
#> → Matched with "HOMER.JunD", PSSM correlation = 0.756415207832166
#> → Matching SCENIC.predrem__nrMotif2250
#> → Matched with "HOMER.CRE", PSSM correlation = 0.674601477662212
#> → Matching SCENIC.cisbp__M00006
#> → Matched with "HOMER.HIF2a", PSSM correlation = 0.660655936327649
#> → Matching JOLMA.MESP1_di_DBD
#> → Matched with "HOMER.MyoG", PSSM correlation = 0.697353340588001
#> → Matching SCENIC.cisbp__M02099
#> → Matched with "HOMER.Lhx3", PSSM correlation = 0.822173337449173
#> → Matching SCENIC.scertf__morozov.MGA1
#> → Matched with "HOMER.Tcf4", PSSM correlation = 0.836515311593604
names_map
#> HOCOMOCO.NF2L1_MOUSE.H11MO.0.C
#> "JunD"
#> JASPAR.GATA2
#> "GATA3_2"
#> JASPAR.TBX1
#> "Tbet"
#> JASPAR.TREE1
#> "CES_1"
#> JOLMA.MESP1_di_DBD
#> "MyoG"
#> SCENIC.cisbp__M00006
#> "HIF2a"
#> SCENIC.cisbp__M00066
#> "PU_1"
#> SCENIC.cisbp__M02099
#> "Lhx3"
#> SCENIC.hocomoco__ZBT18_HUMAN.H11MO.0.C
#> "E2A"
#> SCENIC.kznf__CTCF_ENCODE.57_ChIP-seq
#> "SeqBias_A"
#> SCENIC.neph__UW.Motif.0048
#> "Ptf1a"
#> SCENIC.neph__UW.Motif.0188
#> "Oct4"
#> SCENIC.neph__UW.Motif.0639
#> "Atoh1"
#> SCENIC.predrem__nrMotif2250
#> "CRE"
#> SCENIC.scertf__morozov.MGA1
#> "Tcf4"
#> SCENIC.swissregulon__hs__ESR2
#> "Tbx5"
#> SCENIC.taipale__PITX1_DBD_NYTAATCCN_repr
#> "GSC"
#> SCENIC.taipale_cyt_meth__BHLHE23_ANCATATGNT_FL_meth
#> "HLH_1"
#> SCENIC.taipale_cyt_meth__LHX4_NTAATTAN_FL_repr
#> "Lhx3.2"
#> SCENIC.transfac_public__M00410
#> "Oct2"
traj_model <- rename_motif_models(traj_model, names_map)
#> Warning in eval(family$initialize): non-integer #successes in a binomial glm!
#> Warning: glmnet.fit: algorithm did not convergeExporting the model
You can export the minimal model representation to a list of PBM in order to use infer its parameters on new data:
pbm_list <- traj_model_to_pbm_list(traj_model)
#> ℹ Computing motif energies for 20 motifs on 129963 normalization intervals
pbm_list
#> $Atoh1
#> a <PBM> object named "Atoh1" with 15 positions (`@pssm`)
#> Energy normalization max = -16.7697998926721 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $GATA3_2
#> a <PBM> object named "GATA3_2" with 15 positions (`@pssm`)
#> Energy normalization max = -20.5917524566006 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $Tbet
#> a <PBM> object named "Tbet" with 15 positions (`@pssm`)
#> Energy normalization max = -18.4175684223111 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $Oct4
#> a <PBM> object named "Oct4" with 15 positions (`@pssm`)
#> Energy normalization max = -20.1783680776808 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $GSC
#> a <PBM> object named "GSC" with 15 positions (`@pssm`)
#> Energy normalization max = -23.0454344399052 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $Ptf1a
#> a <PBM> object named "Ptf1a" with 15 positions (`@pssm`)
#> Energy normalization max = -17.1134625049322 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $CES_1
#> a <PBM> object named "CES_1" with 15 positions (`@pssm`)
#> Energy normalization max = -18.6210321534491 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $HLH_1
#> a <PBM> object named "HLH_1" with 15 positions (`@pssm`)
#> Energy normalization max = -21.1860887255911 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $PU_1
#> a <PBM> object named "PU_1" with 15 positions (`@pssm`)
#> Energy normalization max = -17.6019069919947 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $SeqBias_A
#> a <PBM> object named "SeqBias_A" with 15 positions (`@pssm`)
#> Energy normalization max = -18.7501484725496 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $Tbx5
#> a <PBM> object named "Tbx5" with 15 positions (`@pssm`)
#> Energy normalization max = -20.8831433498881 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $Oct2
#> a <PBM> object named "Oct2" with 15 positions (`@pssm`)
#> Energy normalization max = -19.3040495565304 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $Lhx3.2
#> a <PBM> object named "Lhx3.2" with 15 positions (`@pssm`)
#> Energy normalization max = -21.4654422091794 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $E2A
#> a <PBM> object named "E2A" with 15 positions (`@pssm`)
#> Energy normalization max = -15.0207500920094 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $JunD
#> a <PBM> object named "JunD" with 15 positions (`@pssm`)
#> Energy normalization max = -21.4395567564327 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $CRE
#> a <PBM> object named "CRE" with 15 positions (`@pssm`)
#> Energy normalization max = -21.6343566895508 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $HIF2a
#> a <PBM> object named "HIF2a" with 15 positions (`@pssm`)
#> Energy normalization max = -19.6442119778802 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $MyoG
#> a <PBM> object named "MyoG" with 15 positions (`@pssm`)
#> Energy normalization max = -19.962137730404 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $Lhx3
#> a <PBM> object named "Lhx3" with 15 positions (`@pssm`)
#> Energy normalization max = -20.0711334552148 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)
#>
#> $Tcf4
#> a <PBM> object named "Tcf4" with 15 positions (`@pssm`)
#> Energy normalization max = -20.3450770525375 (`@max_energy`)
#> Spatial distribution with 11 spatial factors, from position 30 to 470 (440 bp)
#> (`@spat`)
#> Includes a model with 4 coefficients ("high-energy", "higher-energy",
#> "low-energy", and "sigmoid") (`@coefs`)You can now use pbm_list.compute or
pbm_list.gextract:
new_intervals <- data.frame(
chrom = rep("chr1", 3),
start = c(3671720, 4412460, 4493400),
end = c(3672020, 4412760, 4493700)
)
pbm_list.gextract(pbm_list, new_intervals)
#> ℹ Computing energies for 20 PBMs on 3 sequences
#> chrom start end Atoh1 GATA3_2 Tbet Oct4 GSC Ptf1a
#> 1 chr1 3671720 3672020 1.138019 2.985584 0 0.0000000 0.3652249 0.144773
#> 2 chr1 4412460 4412760 0.000000 2.291510 0 2.3218827 1.7040236 0.000000
#> 3 chr1 4493400 4493700 0.000000 2.848635 0 0.5532524 3.4460627 0.000000
#> CES_1 HLH_1 PU_1 SeqBias_A Tbx5 Oct2 Lhx3.2 E2A JunD
#> 1 3.512197 1.737831 0.000000 0 1.0298639 0 3.476509 0 0.5635875
#> 2 0.000000 2.650077 4.233011 0 1.5417980 0 3.918567 0 0.0000000
#> 3 0.000000 2.321180 0.000000 0 0.8919606 0 3.872607 0 0.6992075
#> CRE HIF2a MyoG Lhx3 Tcf4
#> 1 1.7249713 0.0000000 0.53260273 2.811548 0.000000
#> 2 0.8443201 0.4237131 0.78995953 0.000000 4.855682
#> 3 0.3815708 0.0000000 0.06024992 1.404844 0.000000
# directly compute on sequences
seqs <- prego::intervals_to_seq(new_intervals)
seqs
#> [1] "TTCCTCTCCTCCCCTCGCGCGCGCTCCCTCCTCCCGCAGCCTCTCCTCCACCAGCTGACTCCGAGGGAGAGGATGACCTCATCCCTTCCCTTCCAGCTGCCGCCGCTCCCACCCCGGCTGGGGAGGGGCGAGAAGGAGGGCCCGGAGGAGGGGCTGGGATTGAGGGGAGCGGCGGGTGGGGGTGCCTGGCTGGCCAGTGCTGGACGCGGAGGGCAACAGCACGGCAATCGGAGGCCCAGTCCAGGCTCGTGGGATAGCGAAGAGCGTTGAGTGGATTTCCTCGAAGCTGGGGGGATGGGA"
#> [2] "ATCTCTGGAAAGACTTGTGCTGATCTCTCTCTGCCCCTTCCTTGATTCACATCTCAAGGGACCGAGAAGGGAGGGAAAACACCAGTCCAGTATTTCCTATCAGTTCAGCGGGGCAGGAACCGGGAGCTTTTCCACAGGGCTGAGCCTGGCCCTCCACTGAGCAGTGTCTGCATTCCAAGGCTCCAGCCTGTCACCACCCTTCCAATCCCTTTGAAGCTGGGCAAAAGGCCTGCCAACAAGCACCAAACTTGAGAGCTCCTCTGCCAGCCCTGGGAGGGGCTGTTTCCTGCCTGCTTTTCG"
#> [3] "GCTCATGGCTCTCCAGACCGACCCCGAGCTCTGCTATGGCCACGGGACACGCCGCTTCCCCCGACCCTGAGGCAGGGATCGGAAGCTAGCCTGGAGATGCCCAGAGGAACTCGTAAAGCTGAGCGGGTGCTACCCTCCCGCTGCTCTCCTGGTAGACCTAACCCTTCGCCTAATCCGCGCTGGAGATCTACCCAGTGACACTGCGGGTGTCCCCCCGGGCCGCGGGGCCCTTTTCTTTATGGACGCGGCCAATGGCGAGGCGGGGGCGGACCGGACCCTAGTCCTTAGGCCCCCGCCCAG"
pbm_list.compute(pbm_list, seqs)
#> ℹ Computing energies for 20 PBMs on 3 sequences
#> Atoh1 GATA3_2 Tbet Oct4 GSC Ptf1a CES_1 HLH_1
#> [1,] 1.138019 2.985584 0 0.0000000 0.3652249 0.144773 3.512197 1.737831
#> [2,] 0.000000 2.291510 0 2.3218827 1.7040236 0.000000 0.000000 2.650077
#> [3,] 0.000000 2.848635 0 0.5532524 3.4460627 0.000000 0.000000 2.321180
#> PU_1 SeqBias_A Tbx5 Oct2 Lhx3.2 E2A JunD CRE
#> [1,] 0.000000 0 1.0298639 0 3.476509 0 0.5635875 1.7249713
#> [2,] 4.233011 0 1.5417980 0 3.918567 0 0.0000000 0.8443201
#> [3,] 0.000000 0 0.8919606 0 3.872607 0 0.6992075 0.3815708
#> HIF2a MyoG Lhx3 Tcf4
#> [1,] 0.0000000 0.53260273 2.811548 0.000000
#> [2,] 0.4237131 0.78995953 0.000000 4.855682
#> [3,] 0.0000000 0.06024992 1.404844 0.000000Running IceQream on your own data
To run IceQream on your own data, you will need to provide the following inputs:
- Genomic positions of peaks (as a dataframe with columns
chrom,start,end,peak_name), optionally it can have aconstcolumn indicating constitutive loci. - ATAC scores (as a matrix with rows corresponding to peaks and columns corresponding to bins).
- (Optional) Additional features (as a data frame with rows corresponding to peaks and columns corresponding to features).
You can then follow the steps outlined in this vignette to compute motif energies, run the regression and analyze the results.